

Amazon EKS에 대한 심층 분석
EKS를 경험하며 다른사람에게 EKS를 어떻게 설명하면 좋을지 고민한적이 있었습니다.
자료를 찾던 중 다소 시간이 지났지만 AWS re:Invent 2021 에서 Deep dive on Amazon EKS 주제로 발표한 영상이
간략하면서도 핵심적인 내용을 다루고 있어서 보물을 발견한 기분이였습니다.
여기 발표 영상을 Rewind 하며 하나씩 살펴보는 것 만으로 의미있는 시간이 될 거라 생각하며 저와 함께 EKS 여정을 함께합시다.
Why EKS?
EKS 관련하여 저 자신이 가장 처음 궁금해하던 질문이면서 다른 사람들이 제게 빈번하게 했던 질문으로 "Kubernetes 클러스터를 Native로 구성하기보다 왜 EKS를 사용하는지?" 였습니다.
누군가가 제게 EKS를 사용해야 하는 가장 큰 이유 3가지를 묻는다면 저는 보안, 안정성, AWS 서비스와의 통합을 이야기하겠습니다.
실제로 Kubernetes 클러스터를 운영하는 것은 아주 큰 모놀리스 서비스 플랫폼을 운영하는 것처럼 간단한 작업이라도 고려해야 할 영향도가 많고, 이에 따른 오버헤드가 상당히 많습니다.
또한 EKS는 Kubernetes 기술을 최적화 하기 위해 바닐라 업스트림을 사용합니다.
- 바닐라 업스트림: 사소한 변경도 포함되지않은 Native Kubernetes 버전을 기반으로 upstream 합니다.
EKS tenets
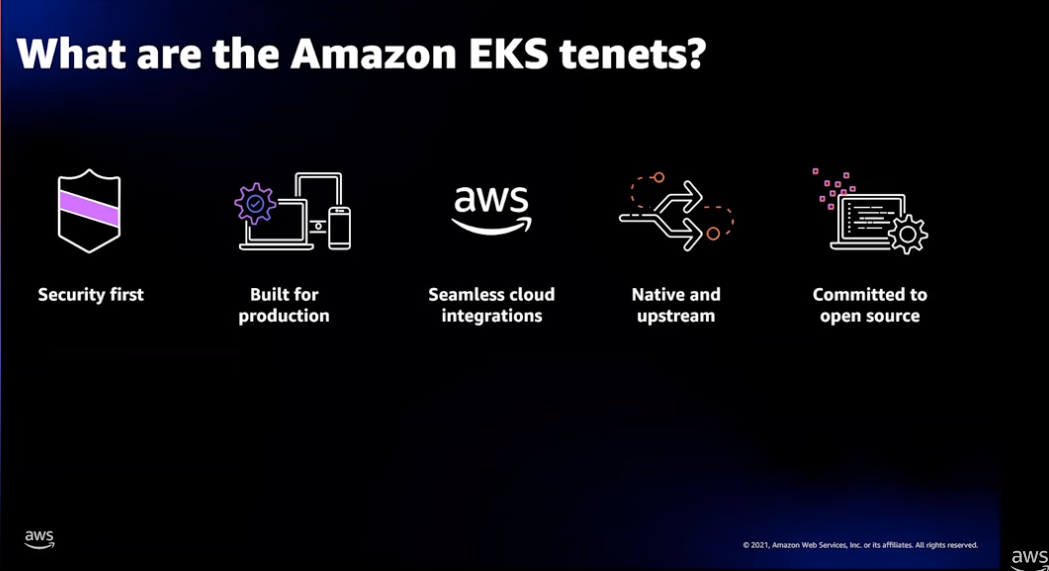
EKS 서비스 원칙으로 보안, 태생부터 상용서비스, 원활한 AWS 서비스와 통합, 바닐라 업스트림, 커뮤니티와 동반 성장입니다.
AWS는 이 원칙들로 EKS 클러스터가 더 적은 오버헤드로 더 나은 효율을 내기위해 그들이 가지는 보안, 운영, 확장에 관련된 전문 기술 들을 활용하고 있습니다.
Security
AWS에서 EKS 제품에 가장 많은 노력을 쏟는 영역이 보안입니다. 보안 관련된 업스트림에서 OS 및 API 패치와 보안 관련된 기술들과의 통합 그리고 변경사항에 대한 테스트로 많은 시간을 할애하고 있습니다.
EKS 책임 공유 모델
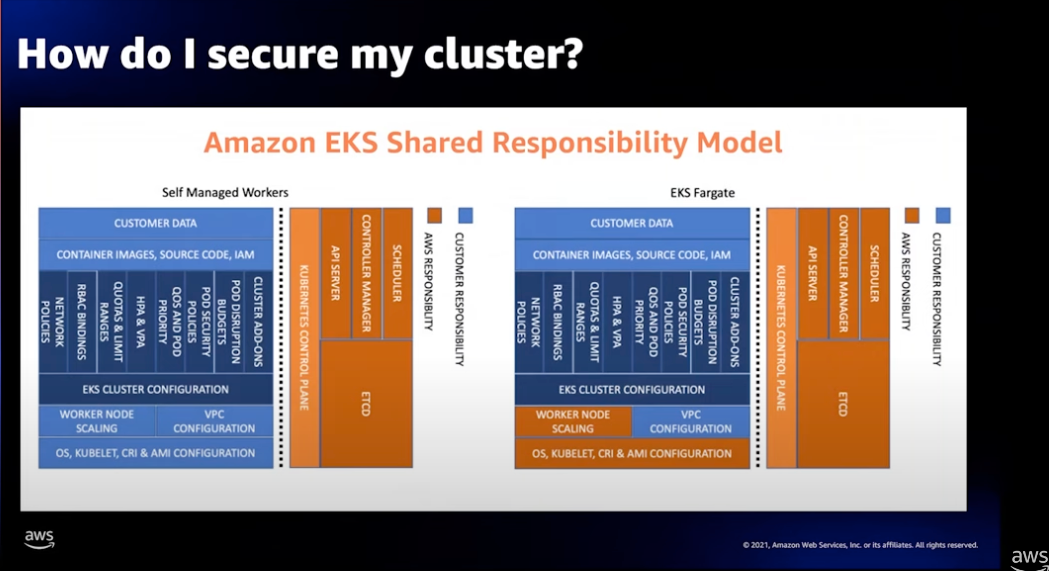
위 다이어그램은 워크 로드를 위한 Data-Plane을 Self Managed 방식과 Fargate 방식을 사용했을 때 AWS 책임 공유 모델을 설명합니다.
공통적으로 Control-Plane을 AWS가 책임지고 있습니다. 만약 여러분이 Kubernetes 클러스터를 직접 구현한다면 가장 큰 운영 오버헤드가 이 부분에서 발생할것입니다.
Control-Plane은 Kubernetes 운영을 위한 핵심 컴포넌트인 API 서버, 스케줄러, 컨트롤러 관리자, etcd로 구성됩니다. EKS는 이것과 관련된 보안을 먼저 담당합니다.
여기에는 개선된 업스트림에 보안 관련된 문제가 있는지 검증하고, etcd 등 중요한 정보는 AWS KMS를 통한 암호화를 적용하여 관리하고 있습니다.
클러스터에서 민감한 데이터의 보호
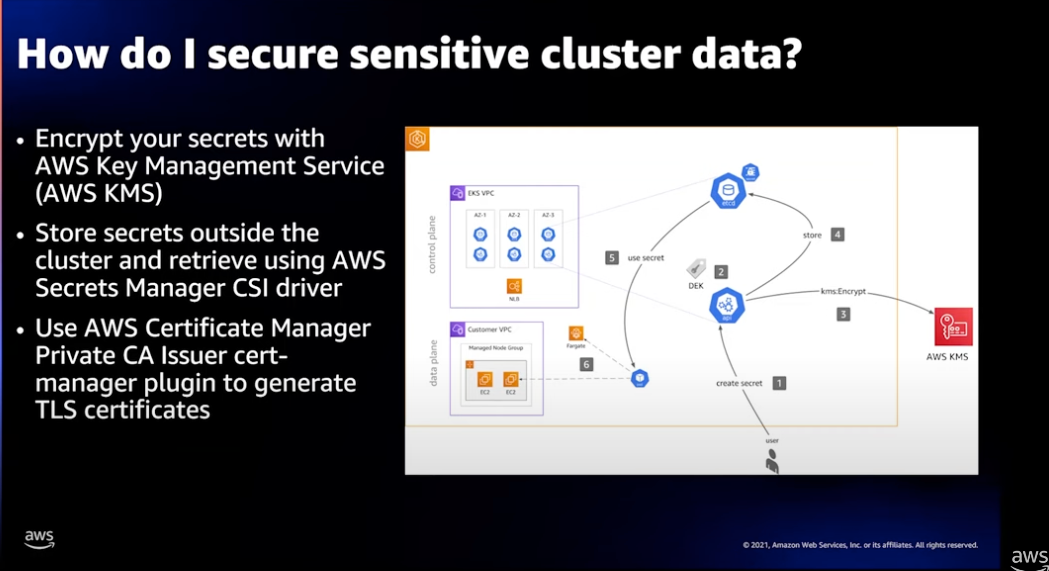
Data-Plane은 서비스 워크 로드를 위한 컴포넌트로 사용자를 위한 민감한 데이터와 네트워크 패킷 전송에 관련된 보안이 적용됩니다.
- 각각의 Pod를 위해 제한된 IAM 접근을 정책을 적용합니다. (인터넷 서비스를 위해 Worker Node에 IAM 접근 정책을 할당하지 않습니다.)
- 외부에 저장되는 민감한 데이터를 위해 Secrets Manager를 사용하여 암호화하고 Secrets Manager CSI 드라이버로 액세스 합니다.
- 네트워크 구간의 암호화 통신을 위해 AWS Certificate Manager로 인증서를 만들고 TLS 프로토콜을 적용합니다.
Public 구간은 ACM 을통해 쉽게 적용할 수 있으며, Private 구간은 private TLS Issuer 플러그인을 제공하여 네트워크 구간의 암호화 통신을 적용할 수 있습니다.
클러스터 액세스를 위한 앤드포인트 제한
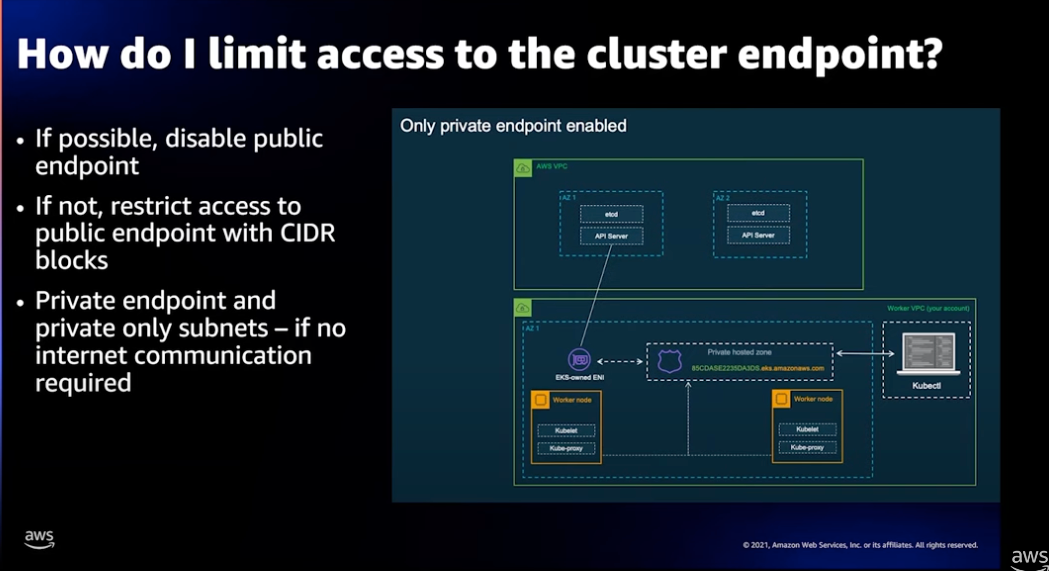
EKS 클러스터를 액세스하는 앤드포인트로 Public 및 Private 앤드포인트가 있습니다.
-
Private 앤드포인트: VPC 내부에서만 액세스 할 수 있으므로 강화된 보안 방식입니다. 상용 서비스를 제공한다면 Private 앤드포인트로 EKS 를 구성하는 것을 권장합니다. 덧붙여 PrivateLink를 사용 하여 S3, ECR 과 같은 여러 AWS 서비스와 안전하게 통합됩니다.
-
Public 앤드포인트: 모든 인터넷 사용자가 접근할 수 있으므로 보안상 권고하지 않습니다.
PoC 및 테스트용도로 사용하는것이 좋으며 IP CIDR 블록을 통해 정의된 IP 에 대해서만 접근하도록 제한할 수 있습니다.
하지만, 해커가 CIDR 블럭을 알게된다면 얼마든지 IP를 변조하여 공격 할 수 있으므로 보안상 권고하지 않습니다.
Worker Node를 위한 보안

- Worker Node를 위한 보안으로 컨테이너를위한 OS 최적화된 관리형 AMI 사용하면 좋습니다. 특히 Bottlerocket은 Linux 기반으로 컨테이너 런타임이 최적화 되어 있는 가장 최신의 기술입니다.
- Worker Node는 상태를 변경할 수 없도록 운영하는것이 좋습니다. 클러스터 버전업이나 OS 보안 패치 등 새로운 AMI로 변경하는 경우에 현재 운영중인 Worker Node를 수정하는 전략이 아닌 새로운 EC2 Worker Node를 생성하고 워크로드를 이전하는 전략이 좋습니다.
- Worker Node 관리를 위해 SSH 포트를 오픈하는것 보다 AWS SSM을 사용합니다.
- Custom AMI를 사용하는 경우 AWS CIS 벤치마크를 통해 검증하는 게 좋습니다.
- 가능하다면 워크로드를 책임지는 Data-Plane 역시 EC2 Worker Node가 아닌 AWS Fargate로 구성하면 AWS에 책임을 넘길 수 있습니다.
Pod를 위한 보안
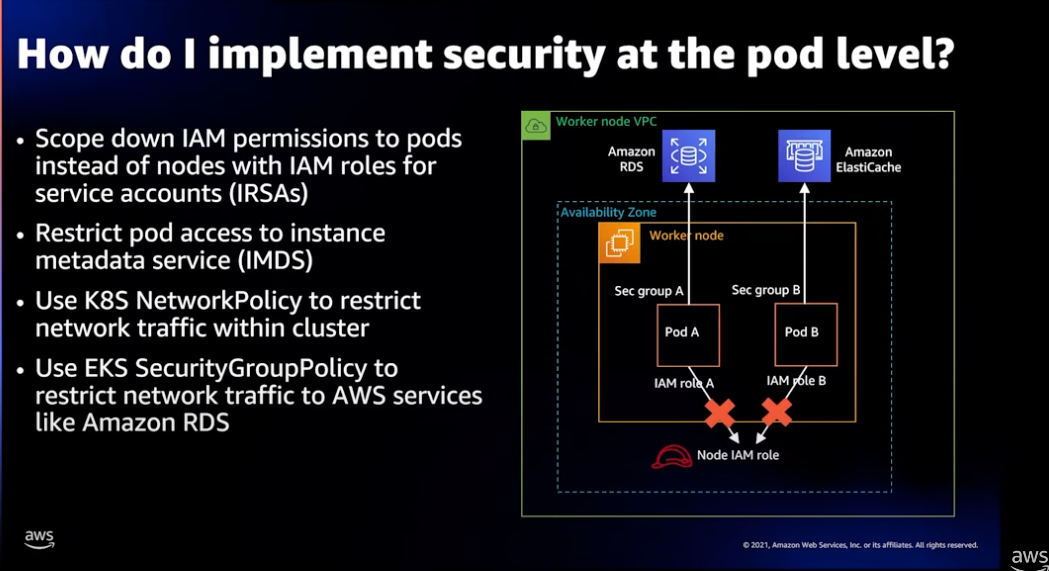
-
IAM 정책 적용:
Worker Node에 IAM 정책을 구성하는 것보다 각각의 Pod 애플리케이션에 대한 IAM 정책을 별도로 구성하는것이 좋습니다.
여기에는 최소권한 원칙을 준수하는 IAM 정책 생성과 쿠버네티스 SeviceAccount를 생성하여 IAM 과 바인딩 합니다. -
NetworkPolicy 를 통한 트래픽 제한:
Pod 내부로 들어오거나(Ingress) 외부로 나가는(Egress) 트래픽을 허용하고 거부하는 정책을 설정합니다.
NetworkPolicy는 CIDR 및 포트를 통해 Block 및 제외할 수 있지만 몇 가지 제한이 있습니다. 예를 들어 노드 단위 설정, TLS 설정, 다중포트 적용 등에서 불가능합니다. -
SecurityGroupPolicy 적용:
SecurityGroupPolicy 는 EKS 가 AWS 서비스(RDS, EC, ..) 와의 액세스를 컨트롤하기 위한 보안 그룹입니다.
보안을 위한 추가적인 모범 사례

위의 다이어그램은 하나의 EKS 클러스터에서 여러팀(A,B,C)이 운영하는 워크로드에 대한 예시입니다.
이 경우 각 팀을 위한 RBAC 및 네임스페이스를 사용하여 격리(논리적)하고 쿠버네티스 할당량 및 범위를 사용하여 컴퓨팅 리소스를 제한하는것이 좋습니다.
- 네임스페이스간 트래픽을 모두 거부하는 네트워크 기본 정책을 적용할 수 있습니다.
- RBAC을 통해 각 팀을 위한 제한된 액세스 정책을 적용하고 컨트롤 할수있습니다.
- v1.20 이상인경우 API 서버의 요청 수를 제한할 수 있습니다.
- OPA(Open Policy Agent) 등 Gatekeeper와 같은 도구를 사용하여 팀이 실행할 수 있는 항목을 거버넌스 정책으로 정의하고 제한할 수 있습니다.
- VM 레벨로 격리화가 이루어지는 Fargate 를 사용하는 것도 좋습니다.
참고로, Kubernetes 자체는 싱글테넌트 오케스트레이터 입니다. 그러므로 Tenant 고객에게 ML과 같은 무거운 워크로드를 제공하는 경우에 Namespace 와 RBAC이 완전하게 격리되도록 별도의 클러스터를 생성하여 제공하는 것을 추천합니다.
컴플라이언스 준수

보안책임자는 컴플라이언스 인증을 획득하고 보안 수준을 보장하는 업무가 있습니다. EKS는 이미 산업 규제 대상의 여러 컴플라이언스 표준을 준수하고 인증받았습니다.
Reliability
EKS 가 고가용성 서비스를 보장하고 애플리케이션의 안정성을 보장하는 방법을 소개합니다.
고가용성을 위한 EKS 아키텍처
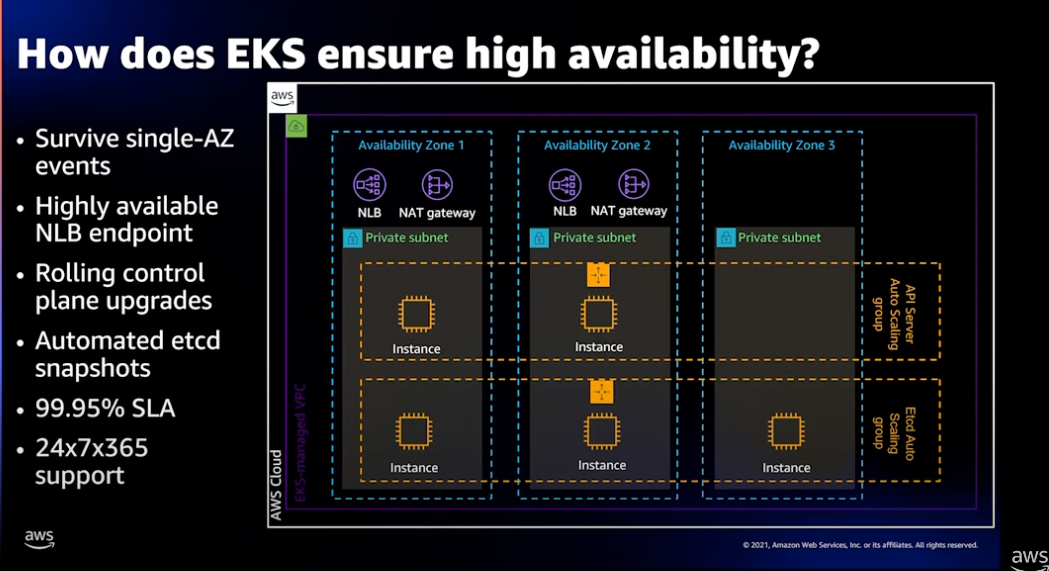
EKS 클러스터는 고가용성을 위해 Control Plane이 기본적으로 3개의 zone에 분산되어 운영됩니다.
- 보안 및 고가용성을 위한 NLB Endppoint로 연결됩니다. (PrivateLink)
- SPoF(Single Point of Failure)를 제거하도록 설계되었습니다.
- 단일 Zone 에서도 문제가 되지않도록 Rolling 업그레이드를 수행 합니다. 1.19 에서 1.20으로 업그레이드 하는 경우, 새로운 인스턴스 교체 방식인 Rolling 업데이트 전략을 사용하므로 업그레이드가 진행되는 동안에도 Endpoint 액세스 할수있습니다.
- etcd 데이터베이스는 자동으로 스냅샷 백업을 진행 합니다.
- AWS는 99.95% SLA 및 24*365 지원을 하고있습니다.
서비스 워크로드를 위한 EKS 운용

위 다이어그램처럼 AWS 에서 담당하는 영역과 사용자가 담당하는 영역으로 구분됩니다.
AWS는 Control Plane 과 Data Plane의 운영 및 성능을 최적화하고 사용자는 클러스터와 워크로드를 위한 로그, 주요한 메트릭 및 지속적인 모니터링으로 서비스를 안정적으로 운영합니다.
Efficiency
컴퓨팅 용량의 크기를 적절하게 조정하여 비용대비 성능을 최대한 끌어내는것은 아주 중요 합니다.
Right Size
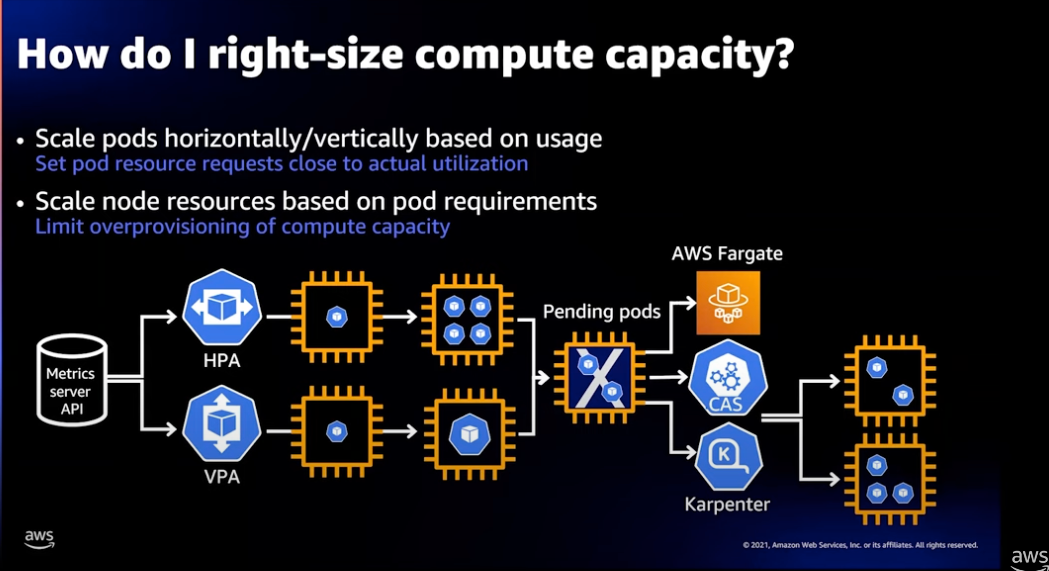
서비스 워크로드에 최대한 근접하게 요청과 제한을 설정할 수 있습니다.
먼저 Pod 의 수직적 VPA(Vertical Pod Autoscaling)자동 확장을 정책으로 Pod 의 용량(CPU, Memory)를 견적하고, 그런 후에 HPA(horizontal Pod Autoscaling) 수평형 자동 스케일링 전략을 적용하는 것이 좋습니다.
(참고로 VPA(Vertical Pod Autoscaling) 와 HPA(horizontal Pod Autoscaling) 수평형 자동 스케일링은 함께 사용할 수 없습니다.)
Pod 에 관한 스케일링 정책을 설정했다면 Worker Node를 위한 자동 확장을 정책을 설정할 수 있습니다.
AWS 관리형 노드 그룹은 EC2 Auto Scaling 그룹과 통합되어 Worker Node를 자동으로 확장 합니다.
또 다른 Worker Node 확장 정책으로 Karpenter 플러그인을 사용할 수 있습니다. Karpenter는 Kubernetes Native한 방식으로 동작하며 대규모 워크로드에서 Worker Node를 아주 빠르게 확장 및 축소를 할 수 있습니다.
Worker Node 관리 및 운용에 전혀 신경 쓰고 싶지않으면 간단하게 EKS Fargate를 사용하면 됩니다.
클러스터 비용 최적화
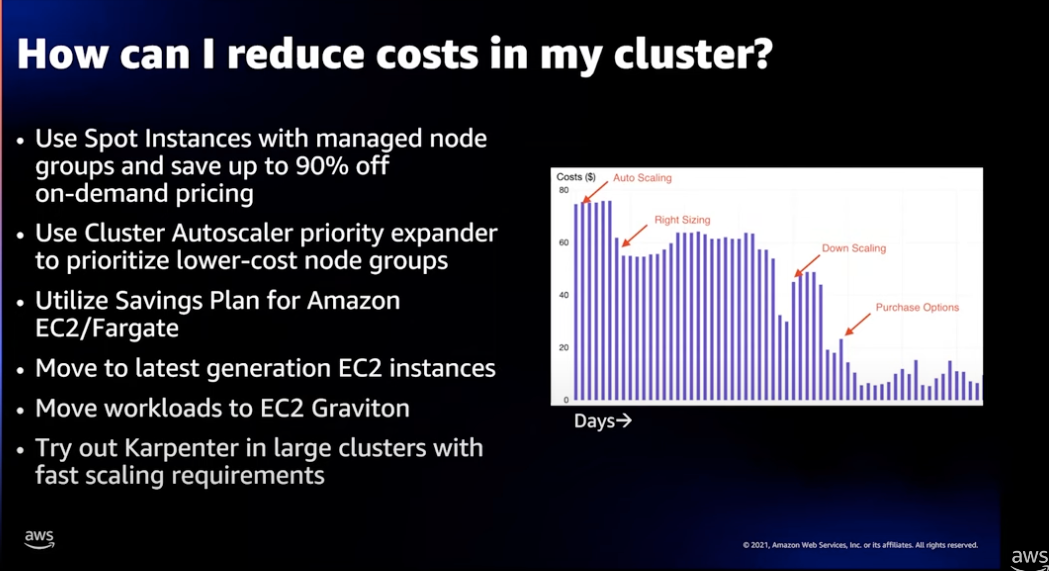
위의 그래프는 고객의 실제 사례를 기반으로 스케일링 정책 - Right Sizing - Down Scaling - Savings Plan 구매 옵션의 흐름으로 클러스터 비용 최적화 여정에 대해 발표한 사례입니다.
이 외에도 컴퓨팅 모더나이즈와 SPOT 인스턴스의 사용으로 비용 최적화를 달성할 수 있습니다.
IPv6 기반 스케일링 전략

EKS는 VPC-CNI(Container Network Interface) 플러그인을 사용할 수 있습니다.
VPC-CNI의 가장큰 장점은 네트워크 성능과 함께 EKS Worker Node와 Pod 의 네트워크 CIDR 대역이 VPC CIDR 대역과 같다는 것입니다.
이 것은 Kubernetes 를 위한 별도의 오버레이(VXLAN, IP-IP 등)없이, VPC Native 하게 Pod간 직접 통신이 가능하게 됩니다.
뿐만 아니라, VPC가 가지는 보안 그룹 및 NACL로 클러스터 환경을 보호할 수 있습니다.
가용성 측면에서 EKS는 IPv4와 IPv6 둘 다 사용할 수 있습니다. Pod 가 확장 되면 VPC CIDR 대역의 IP 가 할당되는데 문제는 IPv4 인 경우 CIDR 대역에 여분의 IP가 부족하면 성능 저하가 발생합니다. 이를 방지하기 위해 IPv6 를 사용하는것이 좋습니다.
부득이하게 IPv4 를 사용해야 한다면 VPC에 CIDR 블럭을 추가할 수 있는 옵션이 있습니다.
적은 수의 큰 클러스터 운용 vs 다수의 작은 클러스터 운용

클러스터 규모 및 클러스터 단위의 확장에 관한 고민입니다. 결론은 상황에 따라 구성해야 합니다.
하나의 클러스터에서 여러 조직의 워커로드를 운용한다면 규모가 있는 적은 수의 큰 클러스터를 운용하는것이 유리하고, SaaS 서비스로 테넌트 수준의 ML 워크로드를 위한 격리는 작은 크기를 다수의 클러스터로 운용하는것이 유리합니다.
일반적으로 가능한 적은 수의 클러스터를 운영하는 것이 운용 부담을 줄이는 길 입니다.
EKS 운용
EKS 버전 업그레이드

AWS 는 EKS 업스트림을 100 ~ 150일 뒤에 이루어지도록 계획하고 있습니다. 여기에는 보안, 성능을 위한 패치가 포함됩니다.
사용자는 1년에 2 ~ 3회 업그레이드 계획을 세우고 EKS 버전을 업그레이드 하는것이 좋습니다.
EKS의 업그레이드를 아주 쉽고 단순하게 할 수 있다는 것입니다.
1.19 에서 1.20 으로 업그레이드 하기 위해 단 한번의 API 호출로 작업이 완료됩니다. 게다가 Managed Node Group 및 Fargate 와 같은 관리형 서비스와 관리형 서비스를 지원하는 플러그인(CSI, CNI) 기능들은 업그레이드 프로세스를 단순화 하였습니다.
하지만 상용 서비스를 위한 실제 워크 로드를 운용하는 EKS 클러스터를 업그레이드하는 경우에 다음을 주의하여야 합니다.
- 가능하면 Test 환경에서 업그레이드 프로세스를 검증 합니다.
- 업그레이드 버전의 변경 내역으로 Deprecated된 kubernetes API는 굵은 글씨로 표기되므로 반드시 확인합니다.
- 업그레이드되는 버전의 EKS 클러스터가 CNI 및 CSI 와 같은 컨트롤러를 보다 세밀하게 제어하기 위해 IAM Role 의 보완을 필요로할 수 있습니다.
- EBS와 같은 퍼시스트볼륨을 사용하고 기존 데이터를 유지해야하는 Worker Node를 업그레이드 하는 경우 특별히 교체에 주의해야 합니다. PV(PersistentVolume) 리소스를 만들 때 persistentVolumeReclaimPolicy 옵션을 “Retain” 으로 하여야 합니다.
EKS 클러스터 액세스 제어 관리

EKS 클러스터를 위한 사용자 액세스 관리를 위해 크게 2가지 인증방식이 있습니다.
-
AWS IAM 인증:
별도의 계정 관리를 위한 저장소가 필요하지 않습니다. 여러 사용자의 액세스 컨트롤을 위해 Assume 역할을 사용하여 제한할 수 있습니다. -
OIDC (Open ID Connect) 인증:
AWS 이외의 Third party ID 시스템이나 SSO 와의 통합 인증을 지원하며 조직에서 관리되는 사용자 또는 O-Auth 클라이언트에 대해 인증을 처리할 수 있습니다.
인증된 사용자에 대한 EKS 클러스터의 Kubernetes 객체를 액세스하는 것은 RBAC(Role Based Access Control)으로 제어합니다.
EKS 클러스터 상태 모니터링
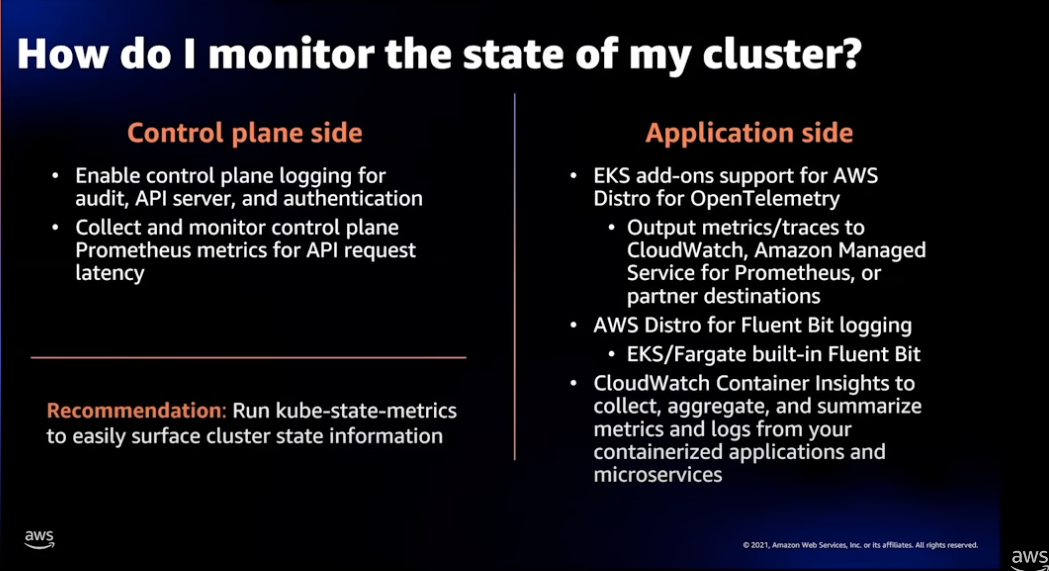
Control Plane 상태를 모니터링 하는게 좋습니다. 이렇게 하려면 Control Plane 로깅을 활성화하여 API 서버, 인증, Audit 등의 로그를 CloudWatch로 적재합니다.
kube-state-metrics 를 통해 쉽게 클러스터 상태정보를 파악할 수 있습니다.
애플리케이션 영역을 모니터링하려면 OpenTelemetry를 사용하는것을 추천합니다. 현재 AWS는 OpenTelemetry를 컨테이너 가시성의 미래라고 생각하며 이것을 전담하는 별도의 팀이 있습니다. 때문에 이것과 관련된 성능 / 통합 / 유스케이스가 지속적으로 공유될 것입니다.
또다른 쉬운 방법으로 CloudWath Insights를 활성화하여 로깅 / 메트릭 등을 쉽게 파악할 수 있습니다.
인터넷 서비스를 위한 네트워크 트래픽 라우팅
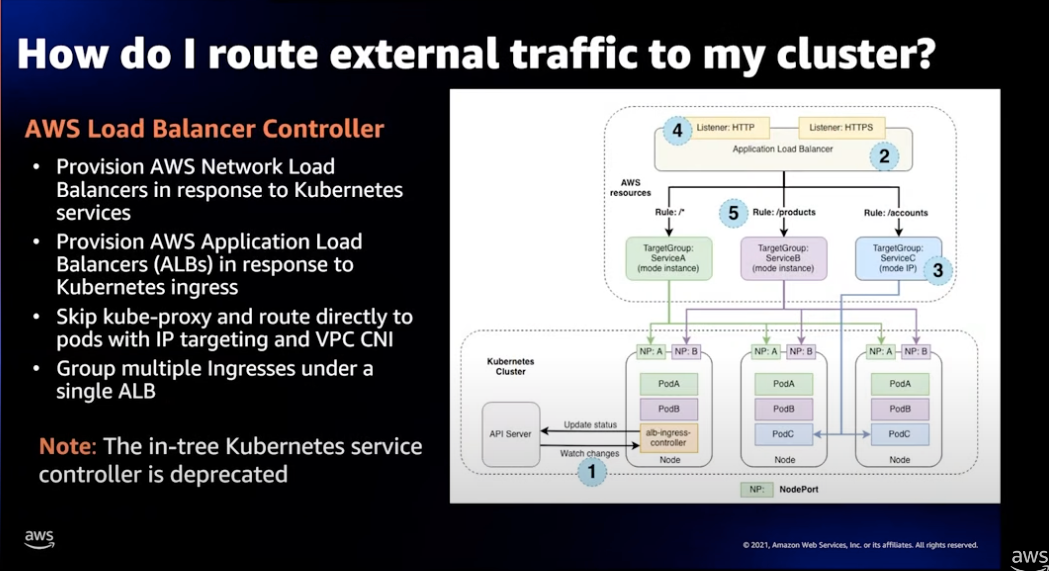
EKS 클러스터 기반 인터넷 서비스를 위해 AWS 로드밸런서 컨트롤러의 사용하는것을 권장합니다.
다음은 AWS 로드밸런서 컨트롤러를 사용하면 얻게되는 여러 잇점입니다.
- AWS Application Load Balancer 를 사용하면 보다 빠른 인그레스 라우팅 및 서비스 응답을 처리할 수 있습니다.
- AWS Network Load Balancer 를 사용하면 보다 빠른 서비스 응답을 처리할 수 있습니다.
- VPC CNI 를 사용하면 ELB 에서 클러스터 Pod 로 직접 트래픽을 라우팅 할수 있습니다.
- Single Application Load Balancer 를 통해 다중 인그레스를 그룹핑하면 비용을 절감할 수 있습니다.
- 비용 절감을 위해 단일 ALB 로 여러 네임스페이스의 서비스로 라우팅할 수 있습니다. (위 다이어그램의 예제가 이것입니다.)
일관된 설정으로 많은 EKS 클러스터 관리

수십 / 수백개의 클러스터를 운영하는경우 일관된 방식으로 관리하는 구성 세트는 GitOps를 사용하는 것을 권고합니다. GitOps는 중앙 저장소(Git)을 통해 운영, 보안, 규정 준수, 애플리케이션 배포 등에 대해 일관된 방식으로 운영할 수 있습니다.
EKS 는 GitOps Configuration set 로 Flux 오퍼레이터를 사용합니다. 이는 eksctl에 포함되어 있습니다.
EKS 내부에서 AWS 서비스를 프로비저닝하고 액세스

EKS는 ACK(AWS Controllers for Kubernetes)를 통해 kubernetes 메니페스트 정의를 통해 AWS 리소스를 정의하고 프로비저닝 할 수 있습니다.
S3, ElastiCache, EMR, MQ, SNS 등 다양한 AWS 서비스들을 일관된 방식으로 프로비저닝 구성이 가능하고 개발자가 Kubernetes 에 익숙한데 AWS에 익숙하지 않다면 ACK로 쉽게 사용할 수 있습니다. (개인적인 의견으로 모든 리소스는 프로비저닝되고 지속적으로 상태를 관리해야 합니다. 그리고 전체 리소스 중 일부가 ACK로 관리 된다면 관리 포인트가 늘어나게 되는 단점도 있습니다.)
Stateful 워크로드 관리

PersistentVolume을 사용하는 Pod와 같이 Stateful 워크로드를 운영하려면 다음을 고려하는것이 좋습니다.
- 고성능(예: RDS 등)을 위한 저장소는 EBS CSI 드라이버를 사용합니다.
- Pod 간 자원 공유가 필요한 경우 EFS CSI 드라이버를 사용합니다.
- EBS 볼륨을 사용하는 워크로드를 스케일링 하려면 단일 AZ 를 대상으로 오토스케일링 그룹을 정의 합니다.
대규모 클러스터 운용에서 서비스 식별
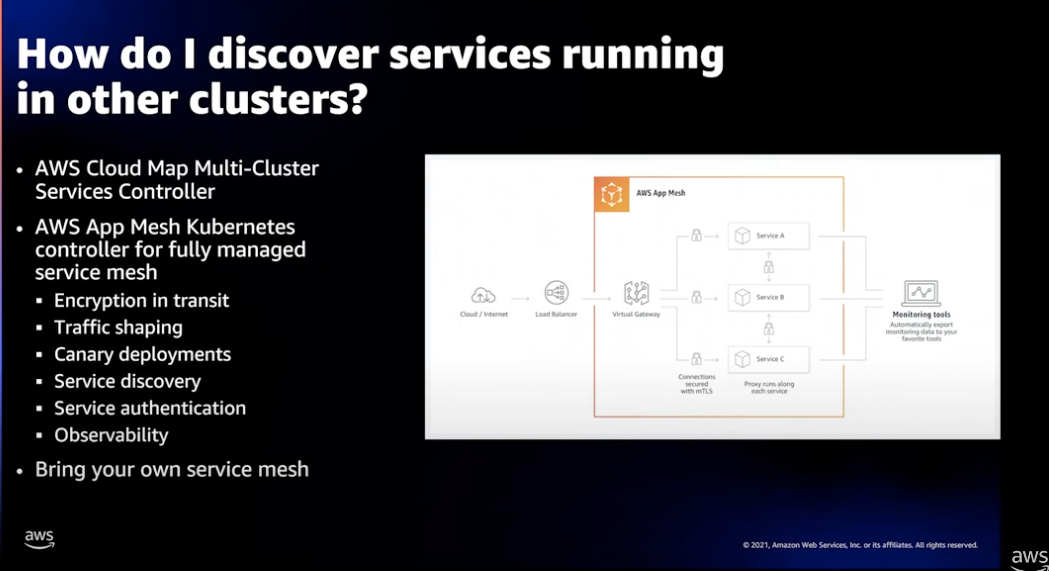
대 규모의 다수의 클러스터가 운용되는 경우 다른 클러스터에서 운영되는 특정 서비스를 쉽게 찾으려면 Cloud Map 서비스를 사용할 수 있습니다.
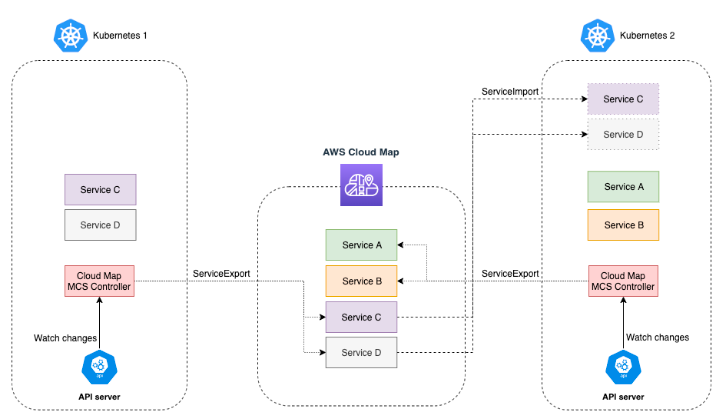
AWS Cloud Map 서비스에 연결된 MCS(Multi-Cluster-Services) 컨트롤러를 통해 디스커버리 상태를 양방향 동기화를 지원하므로 Cluster A 의 a 서비스와 Cluster B 의 b 서비스를 구분하여 식별이 가능합니다.
Portability
일관된 방식으로 EKS 를 운용

AWS는 Kubernetes 환경을 AWS, On Premise, Outposts 에 이르는 완전 관리형부터 EKS Anywhere 같은 하드웨어 런타임 환경에 이르기까지 일관된 방식으로 EKS 클러스터를 배포하고 운영할 수 있도록 지원하고 있습니다.
Conclusion
Deep dive on Amazon EKS를 통해 EKS를 왜 사용해야하는지, AWS가 EKS 서비스를 릴리즈하는데 어떤 철학을가지고 무엇에 주력하는지?를 알 수 있었습니다.
사용자는 맨 처음 EKS와 같은 Cloud의 서비스를 생각할 때 비교적 높은 운영 비용과 기술 스택에 부담을 느낄 수 있겠지만 이 블로그를 통해 EKS 서비스가 빙산의 수면 아래에서 운영되는 Kubernetes 기술들의 복잡함과 통합을 위해 얼마나 큰 노력이 녹아 있음을 이해하고, 왜 EKS를 사용하는 게 좋은지 Built for Production의 가치를 생각하는 시간이었기를 바랍니다.