

AWS Fargate Auto-Scale 정책을 테라폼 코드로 빠르게 적용하여 서비스를 보다 탄력적으로 운영합시다.
Pre-Requisite
시작하기에 앞서 사전에 ECS Fargate 구성이 되어 있어야 합니다.
ECS Fargate 구성은 지난 글 Automation Building AWS Fargate & Deploy application 을 참고 합시다.
Background
AWS 가 제공하는 서비스들을 보면 Elastic 으로 시작하는 서비스들을 많이 볼 수 있습니다.
Elastic 은 서비스 규모에 알맞은 워크로드 크기를 탄력적으로 운영 하는 AWS 의 철학이라고도 할 수 있는데요,
예를 들어 10 명의 사용자가 이용하는 것과 1,000 명의 사용자가 이용하는 서비스의 워크로드는 필요로 하는 리소스의 크기가 상당히 차이가 있습니다.
문제는 워크로드 크기를 고정 할 수 없다는 것 입니다.
서비스 품질 및 운영 비용을 최적화 하기 위해 서비스 이용자가 폭발적으로 늘어나면 이에 대응하여 워크로드를 확장해야 하고 이용자가 줄어들면 축소 해야 하니까요.
AWS 는 이런 문제를 Elastic 서비스에 Scaling 정책 적용을 통해 자동적으로 워크로드 크기를 탄력적으로 확장 하거나 축소 하도록 지원 합니다.
Auto-Scale 배경 및 작동 방식
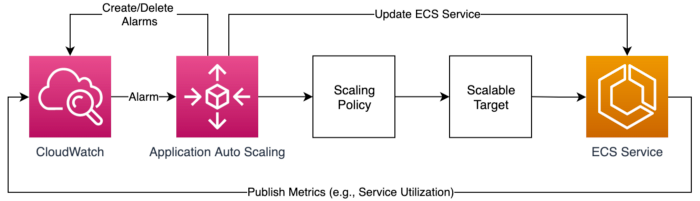
위 그림과 같이 ECS 의 Scaling 서비스는 몇몇 리소스의 협력 으로 Auto-Scale 정책을 통해 워크로드 규모를 조정 합니다.
Auto-Scale 동작 방식의 컨셉은
- EC2, ECS, RDS 와 같은 대상이 되는 서비스에 대해
- CPU, Memory, Network-In / Out 등과 같은 매트릭 측정 지표를 Cloudwatch 를 통해 수집 하여
- 어떤 기준으로 확장(Scale-Out) 또는 축소(Scale-In) 할 것인가?
입니다.
Auto-Scale 정책 구성
우리는 타겟이 되는 서비스에 대해 조정 정책(Scaling Policy)을 구성 할 수 있습니다.
Auto-Scale 조정 정책 은 타겟이 되는 서비스에 대해 인스턴스 축소 와 확장을 위한 설정으로, 조정 정책 유형은 AWS 관리형 메트릭 기준의 대상 추적 조정 정책 과 사용자 정의 기준의 단계 조정 정책이 있습니다.
대상 추적 조정 정책
ECS 에서 대상 추적 조정 정책 은 AWS 관리형 정책으로 ‘ECS 서비스 측정 메트릭’ 의 대상 지표 값이 초과 하는 경우 인스턴스를 확장 하고, 미만인 경우 축소 하는 아주 단순하지만 강력한 조정 정책 입니다.
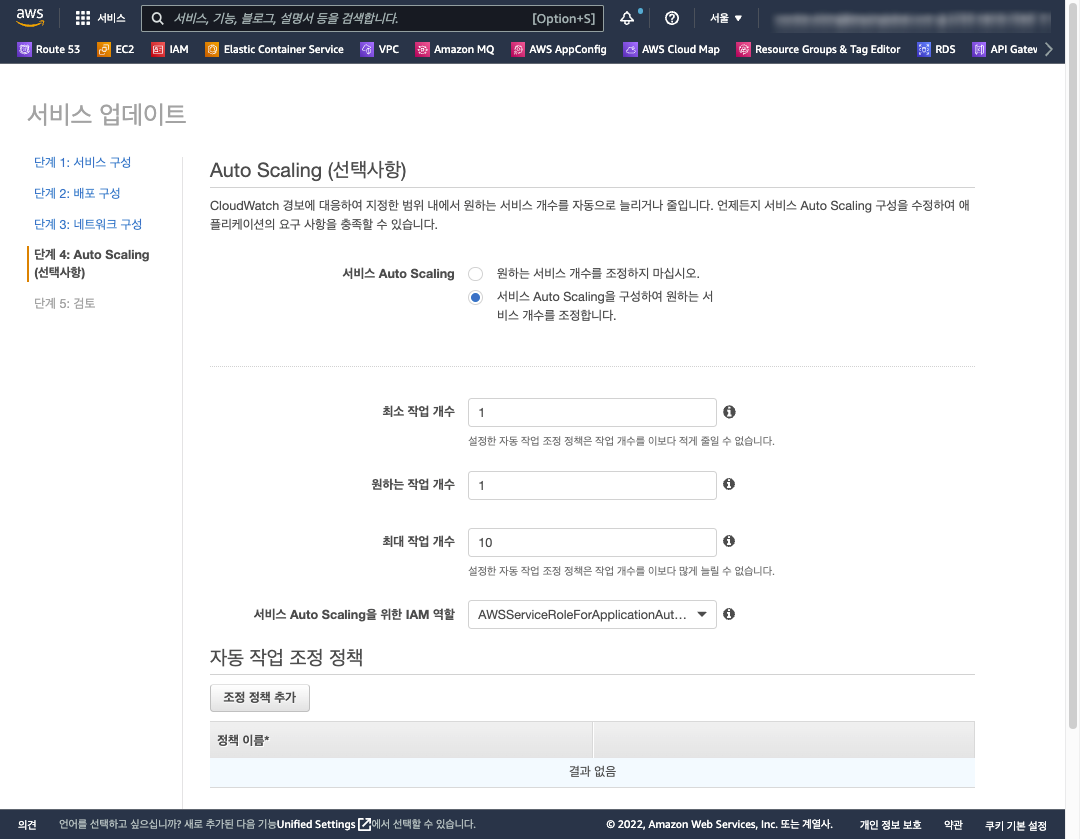
먼저 타겟 서비스를 위한 Scaling 정책 정보로 최소 작업 개수, 원하는 작업 개수, 최대 작업 개수 와 함께 Auto Scaling 을 동작 시키기 위한 권한(IAM 역할)을 설정 합니다.
예시로, 아래 그림과 같이 트래픽이 적은 경우 태스크 수(min_capacity)를 1 로 하고 트래픽이 많을 경우 최대(max_capacity) 10 개 까지 확장 되도록 Scaling Target 정보를 구성 할 수 있습니다.
추가적으로 Auto-Scale 처리를 위해 AWS 의 서비스를 실행 할 수 있는 IAM 권한이 필요 합니다.
IAM 권한은 Application Auto Scaling에 대한 서비스 연결 역할 중 AWSServiceRoleForApplicationAutoScaling_ECSService 를 참조하세요.
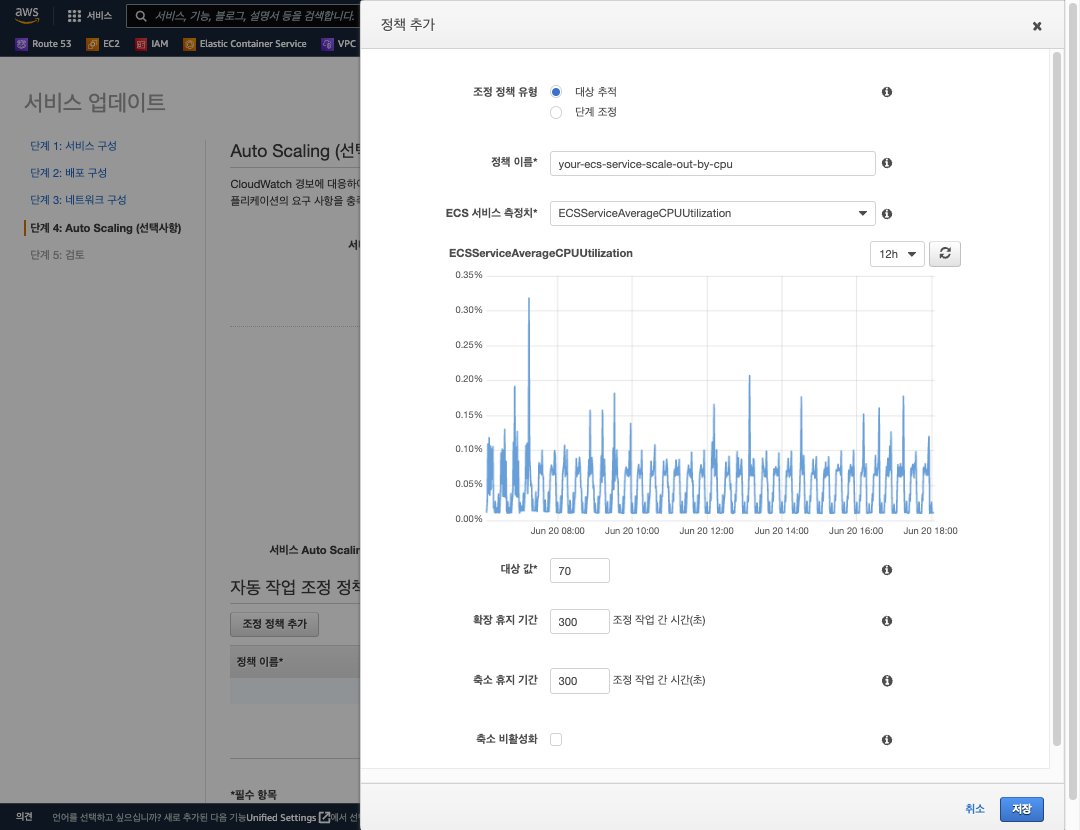
- ECS 서비스 측정 메트릭은 아래와 같습니다.
- ECSServiceAverageCPUUtilization: 평균 CPU 사용율을 기준
- ECSServiceAverageMemoryUtilization: 평균 Memory 사용율을 기준
- ALBRequestCountPerTarget: ALB 를 통해 트래픽이 유입되는 건수 기준으로 ECS 애플리케이션 서비스가 ALB 와 연결 되어 있는경우만 설정이 가능
평균 CPU 사용율 기준 대상 추적 조정 정책의 적용
아래 그림과 같이 Auto-Scale 그룹 기준, 평균 CPU 사용율 70% 를 초과하는 경우에 Scale-Out 되고 미만인 경우에 Scale-In 되도록 구성 할 수 있습니다.
만약 하나의 ECS Task 의 CPU 사용율이 평균 80 % 였다면 Cloudwatch 알랑을 통해 Scaling 조정을 위한 트리거가 발생 하게 되고, 위 조건에 의해 1개의 인스턴스가 추가 되고 Auto-Scale 그룹 기준 평균 CPU 사용율은 40% 으로 낮아질 것으로 예측 됩니다.
그렇다면 확장 이후 CPU 사용율이 70% 미만으로 안정화된 시간이 지속 된다면 Scale-In 트리거가 발생할 수도 있습니다. 여기서 휴지 시간 설정에 의해 빈번한 Scaling 트리거를 방지 할 수 있습니다.
만약 인스턴스가 계속 추가되었음에도 평균 CPU 사용율이 70% 이상이라면 최대 10 개에 도달할 때까지 계속적으로 확장을 시도 할 것입니다.
참고로, 대상 추적 정책의 매트릭 수집은 Cloudwatch 로 하고 있으며 주기는 1분 입니다.
대상 추적 조정 정책 적용에서 고려 사항 을 꼭 읽어 보시고, 특히 지정한 지표(예: ECSServiceAverageCPUUtilization)에 데이터 유입이 부족하면 Scale-In Scale-Out 이 동작하지 않습니다.
평균 CPU 사용율 기준 대상 추적 조정 정책의 Terraform 구현 예시
# AutoScale ECS 서비스 Target Scaling 정책 구성
resource "aws_appautoscaling_target" "scale_target" {
service_namespace = "ecs"
resource_id = "<service>:<ecs-cluster-id>/<ecs-service-id>"
scalable_dimension = "ecs:service:DesiredCount"
min_capacity = 1
max_capacity = 10
}
# 평균 CPU 사용 지표인 'ECSServiceAverageCPUUtilization' 과 타겟 임계(Threahold)값 설정
resource "aws_appautoscaling_policy" "policy_cpu" {
name = "your-ecs-service-scale-out-by-cpu"
resource_id = aws_appautoscaling_target.scale_target.resource_id
scalable_dimension = aws_appautoscaling_target.scale_target.scalable_dimension
service_namespace = aws_appautoscaling_target.scale_target.service_namespace
policy_type = "TargetTrackingScaling"
target_tracking_scaling_policy_configuration {
predefined_metric_specification {
predefined_metric_type = "ECSServiceAverageCPUUtilization"
}
target_value = 70
scale_in_cooldown = 300
scale_out_cooldown = 300
disable_scale_in = false
}
}
대상 추적 조정 정책의 주요 속성
| 속성 명 | 필수 여부 | 설명 |
|---|---|---|
| 정책 이름 | Y | 조정 정책 이름 입니다. |
| ECS 서비스 측정치 | Y | Scale In/Out 을 위한 메트릭 기준 정보 입니다. ECSServiceAverageCPUUtilization, ECSServiceAverageMemoryUtilization, ALBRequestCountPerTarget 중 에 선택이 가능 하며, ALBRequestCountPerTarget 메트릭을 기준으로 하려면 ECS 서비스가 ALB 와 연결되어 있어야 합니다. |
| 대상 값 | Y | Scale In 또는 Scale Out 이 작동 되기 위한 매트릭 기준 값 입니다. |
| 확장 휴지 기간 | N | 한 번의 Scale Out 작업이 완료 되고 다음 번 Scale Out 작업이 시작될 때까지 대기하는 시간이다. (기본 값: 300 초) |
| 축소 휴지 기간 | N | 한 번의 Scale In 작업이 완료 되고 다음 번 Scale In 작업이 시작될 때까지 대기하는 시간이다. (기본 값: 300 초) |
| 축소 비활성화 | N | 축소 비활성화를 체크 하면 Scale In 동작을 하지 않습니다. ((기본 값: 비활성) |
단계 조정 정책 시나리오
정밀한 사용자 요구에 대응하는 정책 구성이 필요한 경우 단계 조정 정책을 구성할 수 있습니다.
먼저 사용자 요구에 대응하는 Cloudwatch 경보를 수집하고 Auto-Scale 대상 애플리케이션을 구성 하여 Scale In/Out 정책을 연결합니다.
예를 들어 평균 CPU 사용량이 50 ~ 70% 인 경우 태스크 5개로 운영 되고, 70% 이상인 경우 10개의 태스크로 운영 되도록 Scaling 정책을 구성 할 수 있습니다.
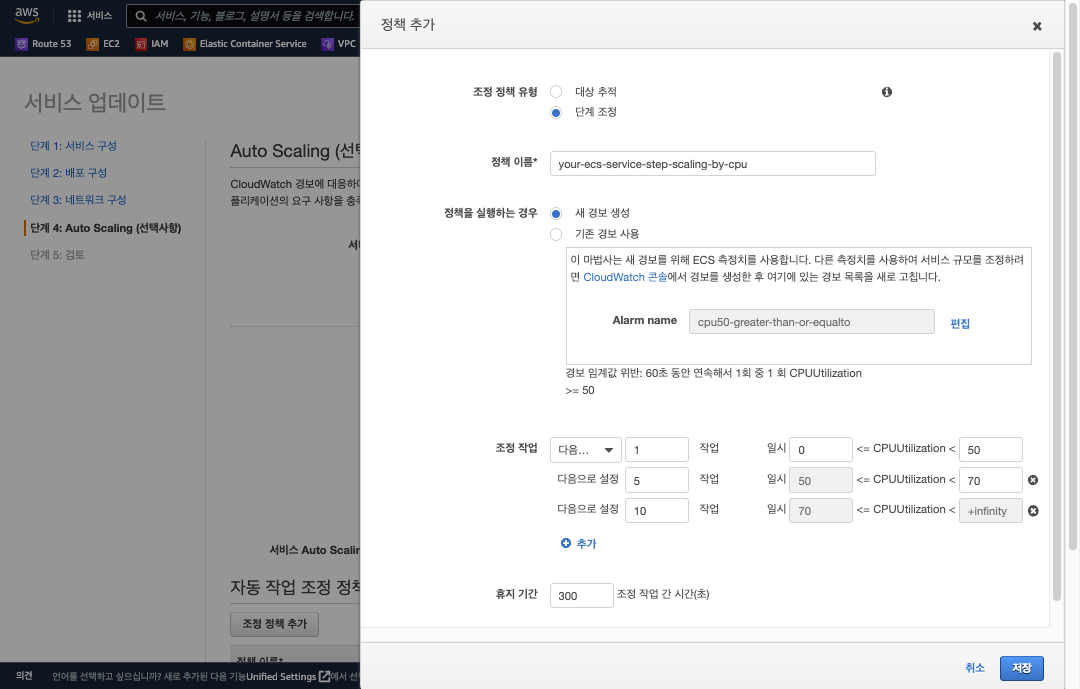
평균 CPU 사용율 기준 단계 조정 정책의 적용
- 먼저 Cloudwatch 에서 1 분내 1 개의 데이터 포인트에 대해
CPUUtilization >= 50조건으로 알람을 발생하도록 Cloudwatch 알람 메트릭을 설정 합니다.
예제 에선 ‘your-ecs-service-scale-out-by-cpu’ 메트릭 알람으로 구성 하였습니다.
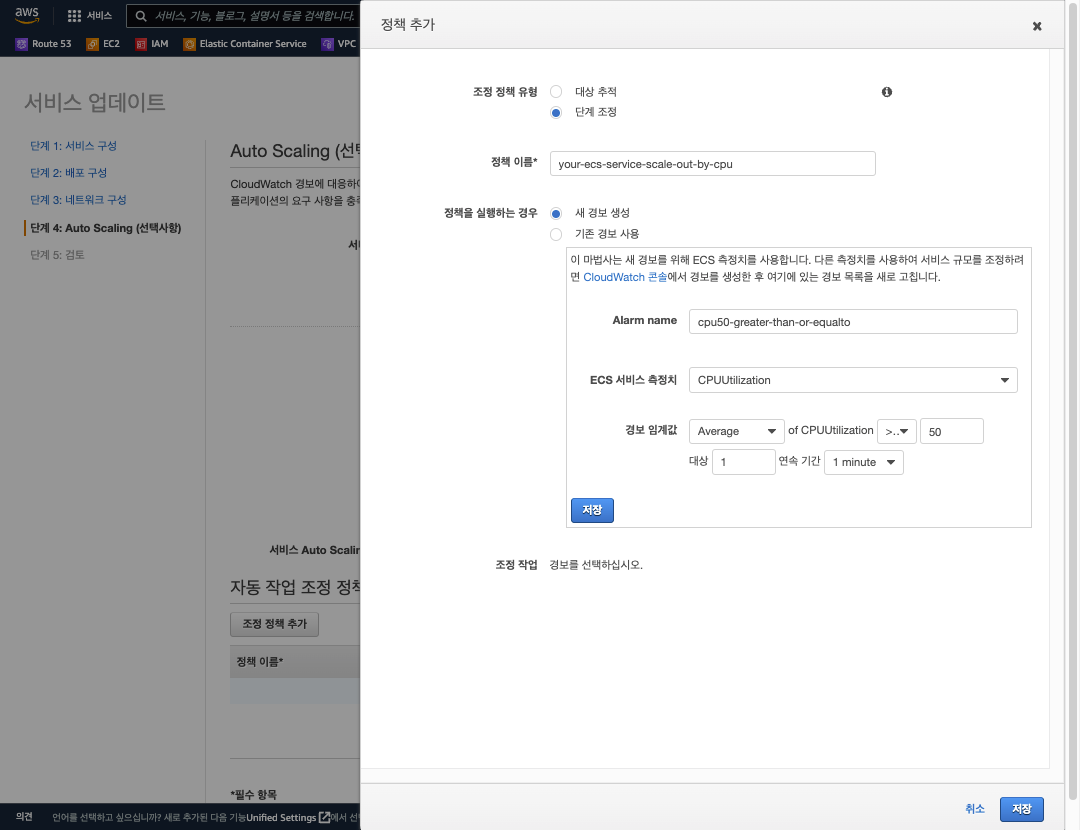
- Scaling 조정 작업 추가를 50 ~ 70% 인 경우 5개의 태스크로 동작 하고, 70% 이상인 경우 10개의 태스크로 동작 되도록 조정 작업을 설정 합니다.
정확한 인스턴스 개수로 Scaling 되도록 하려면 조정 작업을 ‘다음으로 설정’ 을 선택 하여야 합니다.
평균 CPU 사용율 기준 대상 추적 조정 정책의 Terraform 구현 예시
resource "aws_appautoscaling_target" "scale_target" {
service_namespace = "ecs"
resource_id = "<service>:<ecs-cluster-id>/<ecs-service-id>"
scalable_dimension = "ecs:service:DesiredCount"
min_capacity = 1
max_capacity = 10
}
# 단계 조정 정책 추가
resource "aws_appautoscaling_policy" "policy_scale_out" {
name = "your-ecs-service-step-scaling-by-cpu"
resource_id = aws_appautoscaling_target.scale_target.resource_id
scalable_dimension = aws_appautoscaling_target.scale_target.scalable_dimension
service_namespace = aws_appautoscaling_target.scale_target.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ExactCapacity"
cooldown = 300
metric_aggregation_type = "Average"
step_adjustment {
scaling_adjustment = 1 # 양수이면 확장, 음수이면 축소이며 숫자는 인스턴스 갯수를 의미 합니다.
metric_interval_lower_bound = 0.0
metric_interval_upper_bound = 50.0
}
step_adjustment {
scaling_adjustment = 5 # 태스크 수를 5 개로 확장
metric_interval_lower_bound = 50.0
metric_interval_upper_bound = 70.0
}
step_adjustment {
scaling_adjustment = 10 # 태스크 수를 10 개로 확장
metric_interval_lower_bound = 70.0
metric_interval_upper_bound = "" # 값이 없으면 무한대를 의미 합니다.
}
}
}
# CPU 알람 메트릭(경보) 구성
resource "aws_cloudwatch_metric_alarm" "scaleout_cpu" {
alarm_name = "cpu50-greater-than-or-equalto"
alarm_description = "This alarm monitors ECS CPU Utilisation for scaling out"
comparison_operator = "GreaterThanOrEqualToThreshold"
metric_name = "CPUUtilization"
namespace = "AWS/ECS"
period = 60
evaluation_periods = 1
statistic = "Average"
threshold = "50"
alarm_actions = [ "${aws_appautoscaling_policy.policy_scale_out.arn}" ]
dimensions {
ClusterName = "${var.ecs_name}"
ServiceName = "${element(concat(aws_ecs_service.ecs-service.*.name, aws_ecs_service.ecs-service-no-alb.*.name), 0)}"
}
}
단계 조정 정책의 주요 속성
- adjustment : 몇개의 인스턴스를 추가하고 제거 할 것인지 입니다. 추가는 +, 제거는 - 부호와 함께 인스턴스 갯수는 숫자로 기입 합니다.
- adjustment type : 인스턴스를 추가하고 제거하는 조정 정책 유형 입니다.
- ChangeInCapacity : 몇개의 인스턴스를 더하고 뺄 것인가에 대한 사항으로 기존의 인스턴스 수가 3개이고 adjustment 의 값이 5 라면 Auto Scaling 이 동작한 후에는 8개가 됩니다.
- ExactCapacity : 몇개의 인스턴스가 되어야 하는가에 대한 정책으로 기존의 인스턴스가 3 이고 adjustment 의 값이 5 라면 Auto Scaling 이 동작한 후에는 5개가 됩니다.
- PercentChangeInCapacity : 인스턴스의 증가와 감소를 Percentage 으로 적용 합니다. 예를들어 기존의 인스턴스가 2개이고 adjustment 의 값이 100 이라면 Auto Scaling 동작 후에는 4 개가 됩니다.
- cooldown : 인스턴수의 수의 조정 작업을 완료 한 후, 다음번 조정 작업이 시작 될 때까지의 휴지 시간 입니다.
조정 정책 휴지 기간
Auto Scaling 그룹은 인스턴스를 추가(Scale Out)하거나 종료(Scale In)한 후 단순 조정 정책에 의해 시작된 추가 조정 활동이 시작 되기 전에 휴지 기간 동안 대기합니다.
쉽게 말해서 휴지 기간은 조정 정책에 의해 인스턴스 확장 처리(Scale In / Out) 작업이 완료된 이후, 일정 기간 동안 대기 시간을 가짐으로써 스케일링 중에 발생되는 메트릭(CPU, Memory 등) 증가에 의해 또 다시 스케일링 트리거가 발생하는 것을 막기 위함입니다.
예를 들어, CPU 메트릭에 의해 Scale-Out 작업을 진행 또는 지금 막 완료 되었는데, Scaling 조정 작업으로 CPU 사용율이 증가 하여 또 다시 Scale-Out 트리거가 발생 되어 확장 될 수 있는 문제를 방지하기 위해서 휴지 기간을 두게 됩니다.
Reference
Terraform 프로젝트 참고
aws-fargate-magiclub-scaling 프로젝트를 통해 자동화된 방법으로 한번에 Scaling-Policy 를 적용할 수 있습니다.