

AWS DevOps Guru 서비스를 소개해볼까 합니다.
Amazon DevOps Guru 서비스는 지난 AWS re:Invent 2020 에서 처음 소개된 비교적 최신 SaaS 입니다.
지난 블로그에서 DevOps 에 관한 짧은 생각 으로 이야기 했었는데 AWS 는 DevOps 라는 주제를 어떻게 서비스로 풀어가고자 했는지 살펴보도록 하겠습니다.
Introduction
Amazon DevOps Guru 는 머신러닝을 통해 개발자와 운영자가 애플리케이션 가용성을 더 쉽게 개선하고 신속하게 대응 하는 완전 관리형 운영 서비스 입니다.
DevOps Guru 의 머신러닝 알고리즘은 Amazon.com 및 Amazon Web Services(AWS)의 수년간 운영 우수성을 기반으로 하는 기계 학습을 적용하여 애플리케이션 매트릭, 로그 및 이벤트와 같은 데이터를 자동으로 수집 및 분석하여 정상적인 운영 패턴에서 벗어나는 이상 동작을 식별할 수 있다고 소개 합니다.
혹시 Amazon.com 에서 물건을 구매한 경험이 있으신 분들은 느끼셨을 수도 있을텐데, 오랜만에 로그인을 하더라도 내가 원하는 검색 조건이 세팅되어 있고 상품이 추천되는것을 경험 하고 놀란적이 있으실것 같습니다.
ML 우수성을 광고하는 멘트라 할지라도 신뢰감이 오르는건 사실 이네요.
Background
애플리케이션 서비스를 안정적으로 운영하는 오퍼레이터의 운영 업무를 돕기 위해 DevOps Guru 서비스가 출시 되었습니다.
Operator 관점에서 주요한 일들을 살펴보면
- 다양한 로그와 모니터링을 위한 메트릭 등 수 많은 데이터로 압도 되고,
- 이들 운영 데이터의 양 에서 나름대로 의미있는 지표를 선별하여 대시보드를 구성 하고,
- 중요한 지표에 대해서는 임계 수치를 설정하여 수준별 경보를 생성하여 통보 받고,
- 문제가 발생했을 때 복원하기 위해 수 많은 데이터를 분석 하여 수동으로 복원 합니다.
- 경험 많은 전문가라면 복원 계획 및 절차와 Runbook 을 사전에 잘 정리해 두었을 것입니다.
- 근데 최종 보스와도 같은 일은 새로운 아키텍처의 애플리케이션 서비스 또는 클라우드 스택(환경)의 서비스 론칭일 경우 해왔던일들 모두를 다시 정의를 해야 합니다.
게다가 기존 리소스의 구성 변경, CI/CD 에 의한 애플리케이션 배포 에 따른 변화에 대해 지속적으로 메트릭 지표 및 대시보드를 갱신해야 합니다.
오퍼레이터의 업무 루틴에서
- 중요도가 낮은 알림이나 반복적인 알림 이지만 운영환경이라면 무시할 수 없게 되고
- 일상의 긴장되고 피곤한 패턴으로 인해 운영환경에 새로운 스택이 프로비저닝 될 때 적절한 지표를 추가하지 않을 수도 있습니다.
Service value and design principle
Guru 라는 단어에서도 유추하듯이 한 마디로 수년간 Operator 전문가로 활동해 온 사람의 경험을 통한 Insights 를 기반으로 한다면 으로 접근 하였습니다.
조사하면서 4가지 특징을 확인할 수 있었습니다.
1. DevOps 서비스 시작이 아주 쉽고 단순 합니다.
심지어 한 페이지에서 간단한 정보만 기입 하고 활성화 버튼을 클릭 하는 것으로 서비스를 시작 할 수 있습니다.
- 범위 경계를 지정하여 분석하고자 하는 AWS 리소스 선택 합니다.
방식 A: 이 리전의 현재 AWS 계정에 있는 모든 AWS 리소스 분석
방식 B: 나중에 선택 (AWS CloudFormation 스택 또는 AWS 태그를 범위 경계로 분석하도록 특정 AWS 리소스를 지정할 수 있습니다.) - 화면 하단의 ‘활성화’ 버튼을 통해 서비스를 시작 합니다.
2. 오퍼레이터는 대부분 머신 러닝을 통해 제공 되는 인사이트에 대한 대응만으로 많은 것을 해결 합니다.
Guru 전체 시스템은 빠른 해결이라는 아이디어 중심으로 설계되어, 정보를 수집하고 필터링 하여 평균 복원 시간(MTTR) 을 줄이기 위한 권장 사항을 제공 합니다.
- 메트릭, 로그, 이벤트 및 추적과 같은 원천 데이터를 자동으로 수집 합니다.
- 애플리케이션 전반의 메트릭과 로그등을 상관 관계 분석을 통해 근본 문제가 무엇인지 파악 합니다.
- 운영상의 이상 현상 분석은 머신러닝이 하고 결과물로 인사이트 정보를 생성 합니다. 이것을 위해 사람이 머신러닝을 다루거나 알 필요가 없습니다.
3. 무수히 쏟아지는 노이즈 알람을 해결 합니다.
사전 훈련된 기계 학습 모델이 계정과 애플리케이션에 대해 보정처리를 하여 의미없는 경보는 줄여 줍니다. 이상 현상이 발생 할 때 함께 그룹화 하여 동일한 문제에 대해 여러번 경보를 받지 않도록 합니다.
4. 이용자 워크로드에 대응하여 자동적으로 확장 합니다.
지속적인 개선 프로세스를 돕기 위해 이용자의 리소스를 추가 / 제거 하거나 전체 애플리케이션을 추가 /제거 하는 경우 워크로드에 대응하여 자동적으로 확장 합니다.
Cost
AWS 의 대부분의 서비스가 그러하듯 DevOps Guru 또한 사용한 만큼만 요금을 부과합니다.
선불 약정 이나 최소 요금이 따로 없으며 분석된 AWS 리소스와 사용한 DevOps Guru API 호출에 대해서만 요금을 지불하면 됩니다.
과금 기준
- 리소스 요금 그룹 A:
리소스당 0.0028 USD/시간 (S3, Lambda) - 리소스 요금 그룹 B:
리소스당 0.0042 USD/시간 (EC2 인스턴스 기반 서비스) - DevOps Guru API API 호출당 0.000040 USD(API 호출 1만건당 0.40 USD)
- 기타: SNS 설정시 구독 비용, AWS Systems Manager 요금 (DevOps Guru 인사이트에 대한 OpsItem 을 수신 한다면)
3개월간 프리 티어 프로모션
프리 티어 프로모션 혜택은 3개월 동안 매월 리소스 그룹 A 및 B에 대해 각각 7,200 AWS 리소스 시간의 DevOps Guru 분석과 10,000개의 DevOps Guru API 호출 사용량을 무료로 제공 합니다.
참고로, EC2 인스턴스 하나일 때 월 예상 비용이 3 USD 이하로 발생 할 것 같습니다.
System Overview
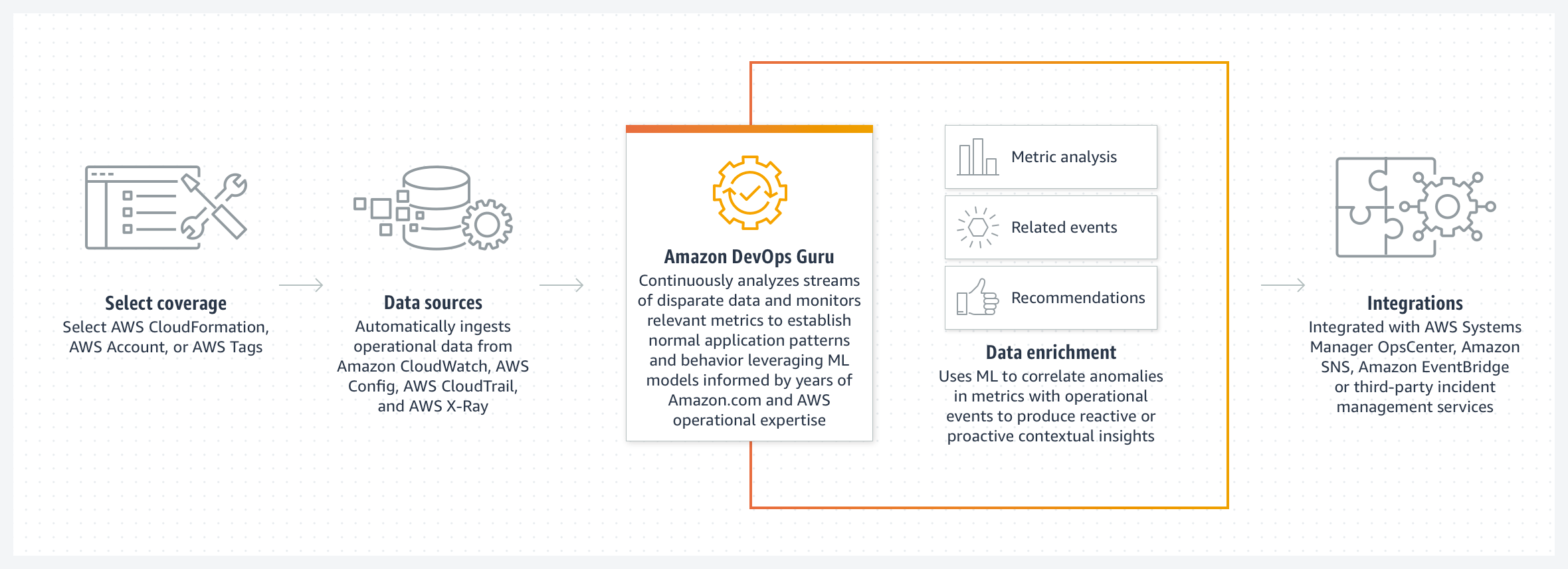
전체 아키텍처는 크게 4가지 컴포넌트로 구분되지만 실제로 사용자가 관여하는 건 DevOps Guru 의 Recommendation 을 보고 처리 하는 것입니다.
4개의 컴포넌트는 다음과 같습니다.
- Select Coverage: DevOps Guru 서비스 시작시 사용자가 범위를 설정 합니다.
- Data sources: AWS 이용자라면 이미 사용하고 있는 CloudWatch, CloudTrail, CodeDeploy, X-Ray 등으로 로그, 메트릭, 이벤트를 통합 수집 하게 됩니다.
- DevOps Guru: 머신러닝을 통해 Insights 를 생산 합니다.
- 대시보드를 통해 전체 시스템 현황을 한번에 파악
- 이상 현상에 대한 지속적인 대응의 통찰력을 제공
- 지속적인 예방 활동의 통찰력을 제공
- 문제 해결을 위한 권장 사항의 안내
- Integrations: AWS Systems OpsCenter 와 Atlassian Ops Jini / Pagerduty 써드 파티와 통합 하면 DevOps Guru 가 생산한 Insights 를 수신하여 효과적인 워크플로우를 적용할 수 있습니다.
DevOps Guru 서비스 살펴보기
DevOps Guru 초기 화면은 Dashboard 메뉴와 함께 시작 합니다.
Dashboard
운영중인 전체 시스템의 Health 상태에 대해 Summary 와 Overview 를 확인 할 수 있습니다.
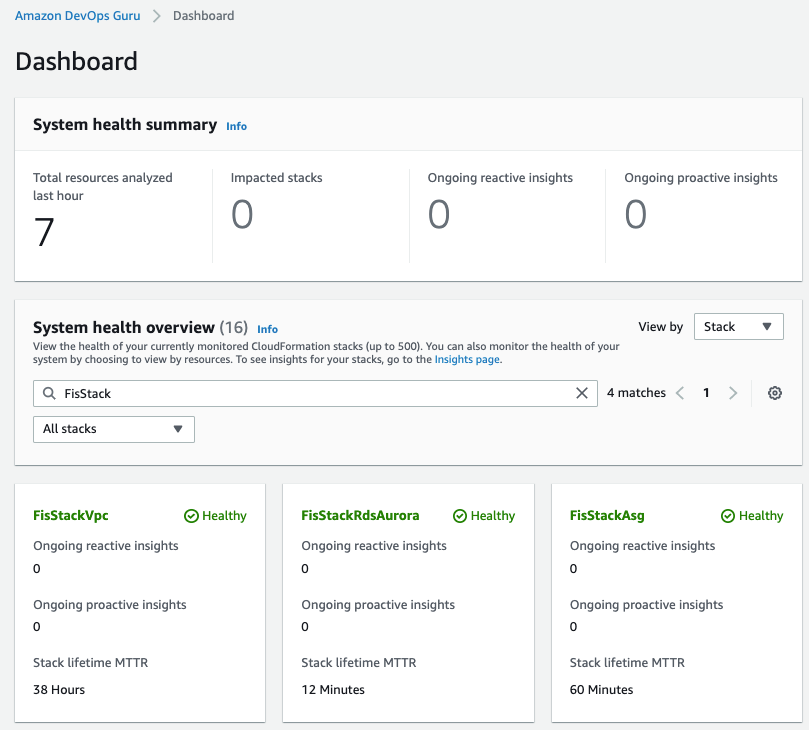
Summary
전체 시스템에 대해 지난 1시간동안 분석된 리소스에 대해 CloudFormation 스택으로 영향받거나 이상 현상에 대한 지속적인 Insights 과 예방을 위한 지속적인 Insights 을 확인할 수 있습니다.
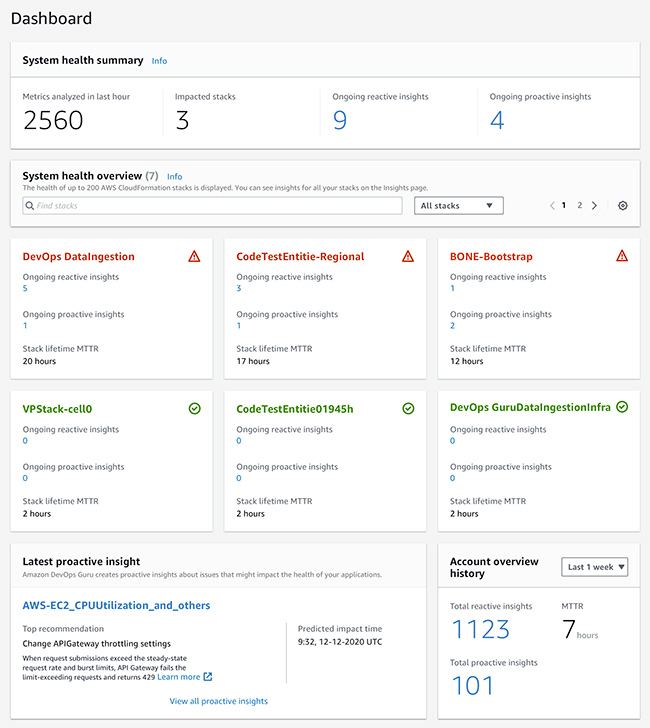
Overview
AWS 계정에 포함되는 애플리케이션 또는 워크로드를 기준으로 애플리케이션 마다 이상 현상에 대한 지속적인 Insights 와 예방을 위한 지속적인 Insights, 그리고 Stack 의 평균 복원 시간(MTTR) 을 확인 할 수 있습니다.
Insights
DevOps Guru Insights 는 다양한 소스로부터 수집된 데이터와 지표, 이벤트 등을 머신 러닝으로 분석 하여 현재 운영중인 애플리케이션의 성능 향상 및 이상 현상을 해결하기위한 권장 사항을 서비스 합니다.
Reactive Insights
현재 이상 현상에 중요한 이벤트가 발생 하였고 사용자에게 적절한 대응을 요구하는 것이 있을 때 Reactive Insights 를 통해 정보가 제공 됩니다.
Insight overview 에서 현재 상태, 영향 받은 스택, 발생 시간, 종료 시간, 갱신 시간을 확인 합니다.
Aggregated metrics
Insights 상세 화면의 집계된 메트릭 정보로 어카운트와 스택의 리소스에 대해 지표별 이상 현상을 집계 하여 이상 현상 지표, 타임라인(발생 시간, 종료 시간) 정보를 제공 합니다.
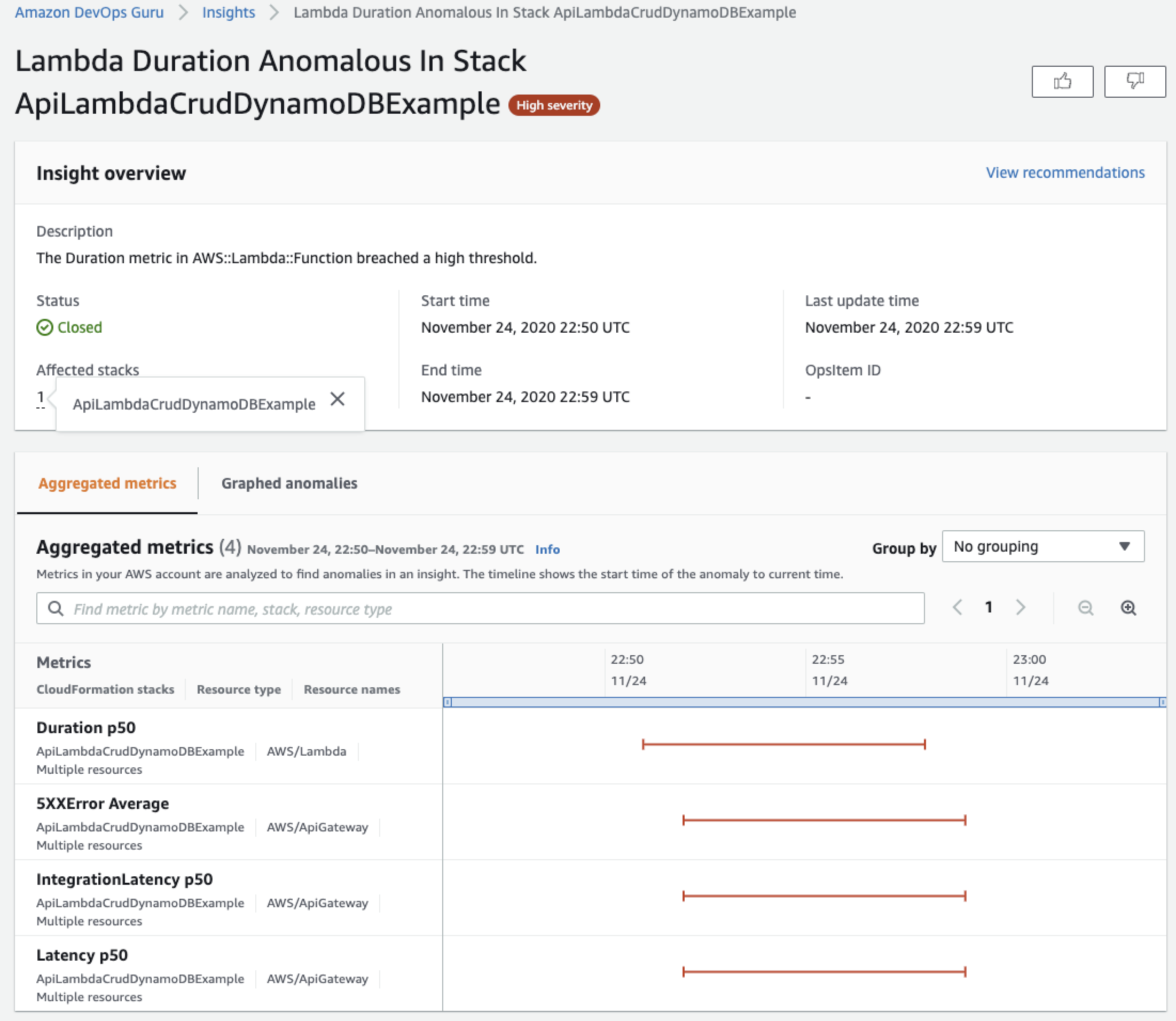
위 예시 화면에서 집계된 4개의 이상 현상에 대한 발생 주체, 발생 시간의 간격을 확인하면 시간별 영향을 준 이벤트의 이상 현상과
근본적인 문제가 CloudFormation 스택 ApiLambdaCrudDynamoDBExample 임을 확인 할 수 있습니다.
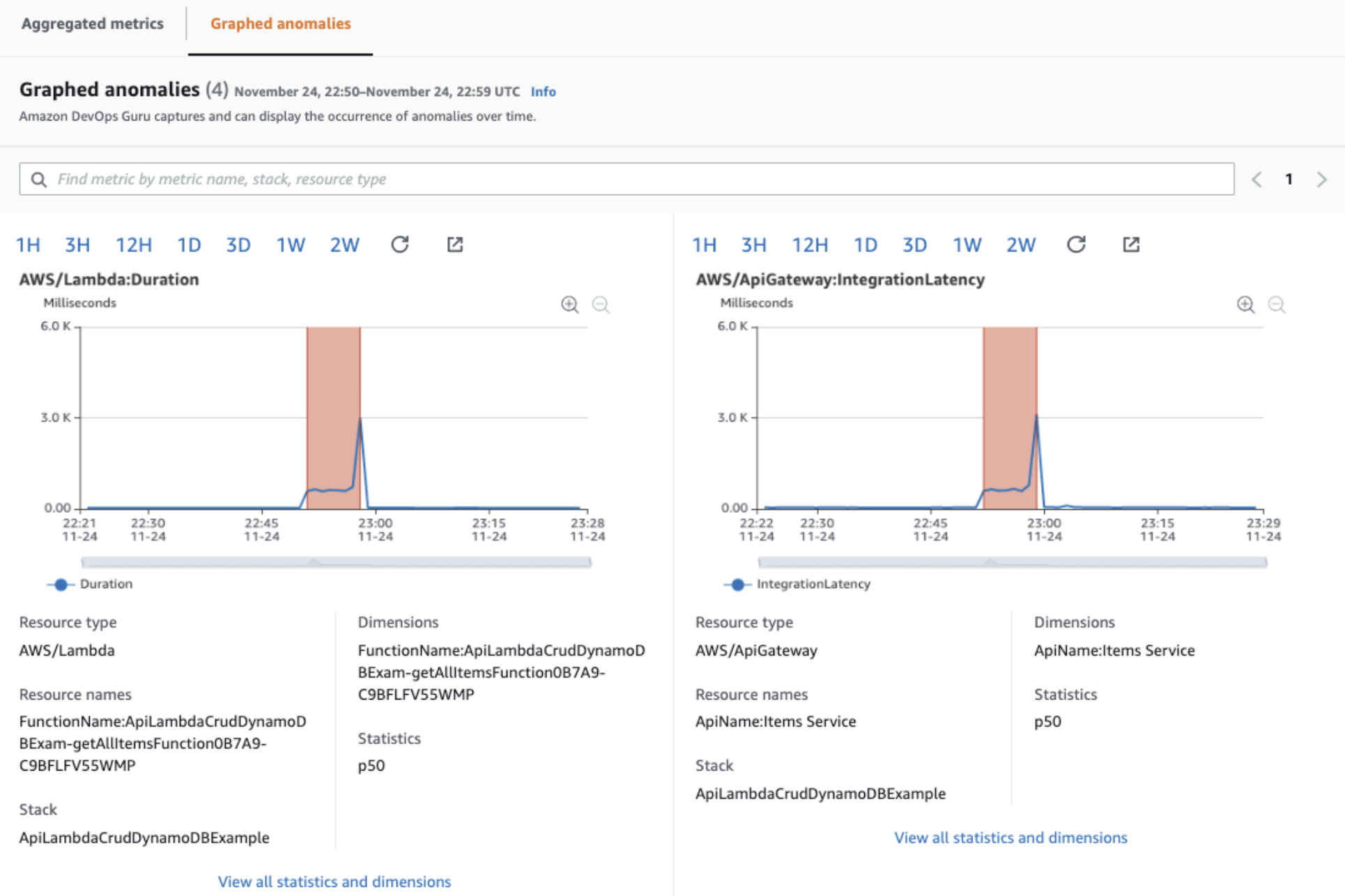
Graphed Anomalies
Cloudwatch 를 기준으로 이상 현상을 그래프로 한눈에 파악할 수 있도록 합니다. 하나 이상의 여러 지표를 확인하고 입체적으로 분석 가능 하기에 이상 현상의 근본 원인을 보다 빠르게 파악 할 수 있습니다.
Relevant events
연관 이벤트에서 Insights 와 관련된 AWS CloudTrail 이벤트를 살핍니다. 주로 리소스의 생성 / 삭제 / 변경에 관한 이벤트가 분석 되어 그래프로 보여집니다.
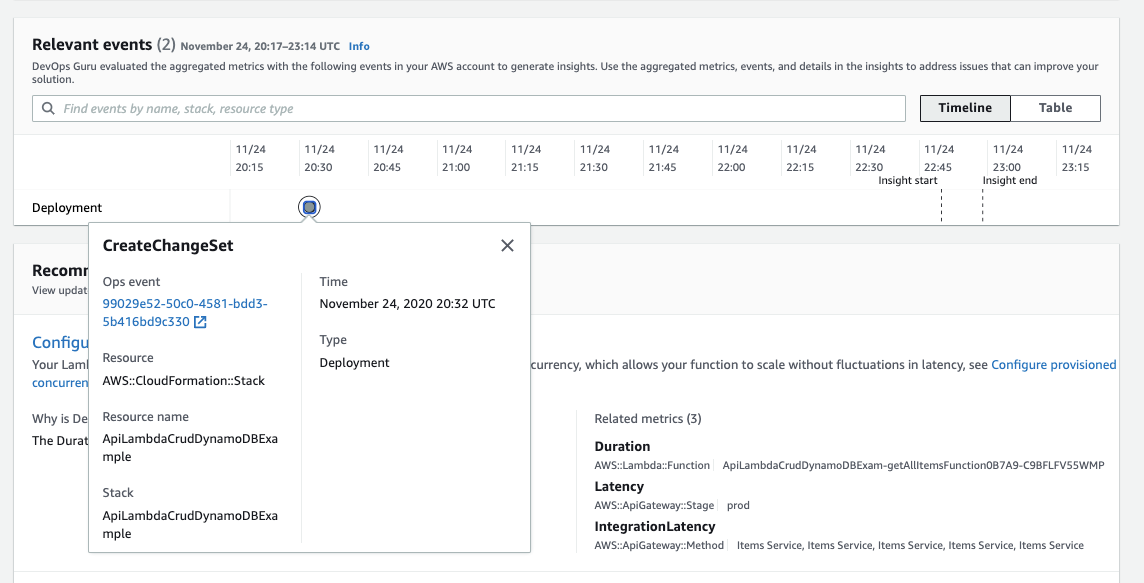
위 화면의 예시에서 이상 현상이 발생된 시간에 CloudFormation 을 통해 새로운 리소스가 프로비저닝 되었음을 확인 할 수 있습니다.
애플리케이션의 경우 CodeDeploy 를 통해 새로운 배포가 일어났다면 이것 역시 연관된 이벤트로 서로 연결되어 보여 지게 됩니다.
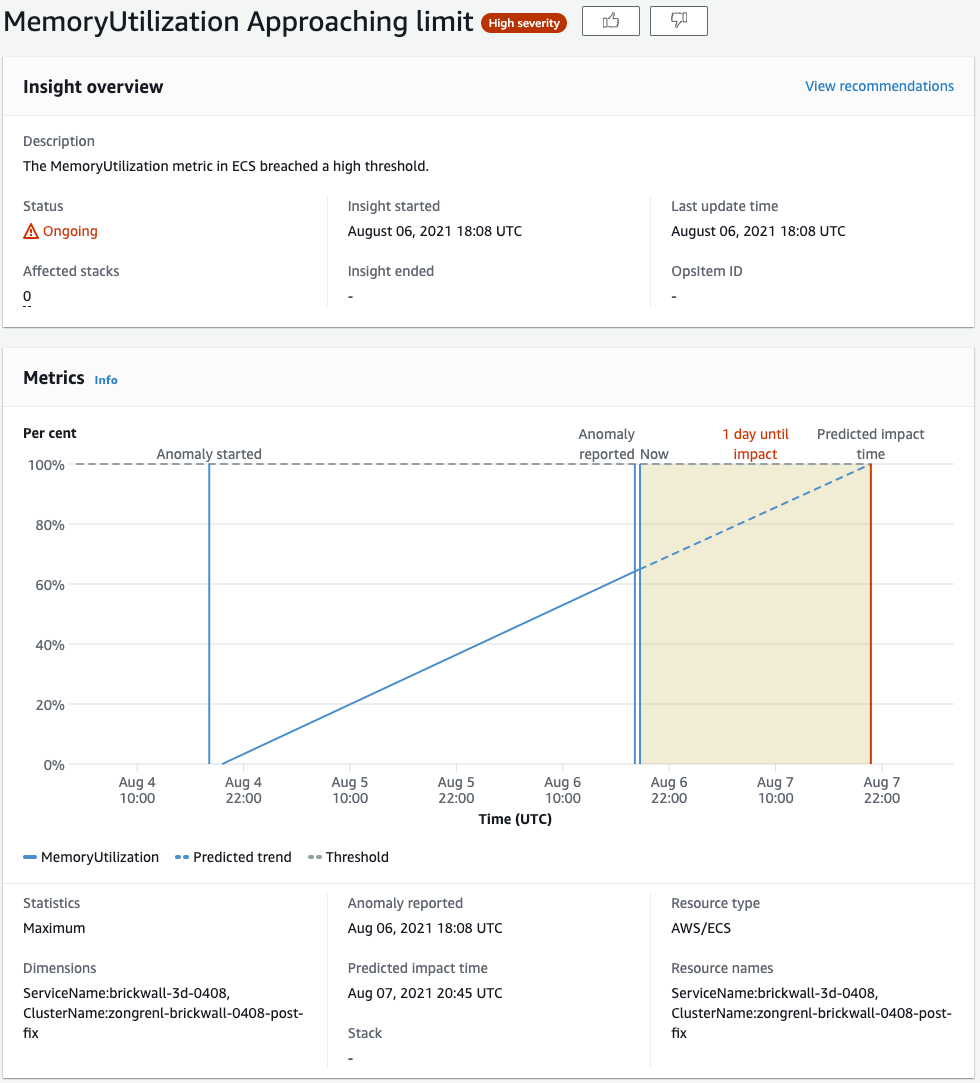
Proactive Insights
Proactive Insights 는 사전 예방적인 활동을 지속적으로 수행하며 리소스의 부족과 같은 메트릭을 핵심적으로 모니터링 하여 길게는 몇 주 전부터 Insights 를 제공 하게 됩니다.
Disk 볼륨 / Memory / CPU 등의 리소스 임계 영역 도달, EIP, ELB, Subnet, EC2 등 제한된 리소스 그룹에서 인스턴스가 임계점에 근접 하는지를 지속적으로 모니터링 하게 됩니다.
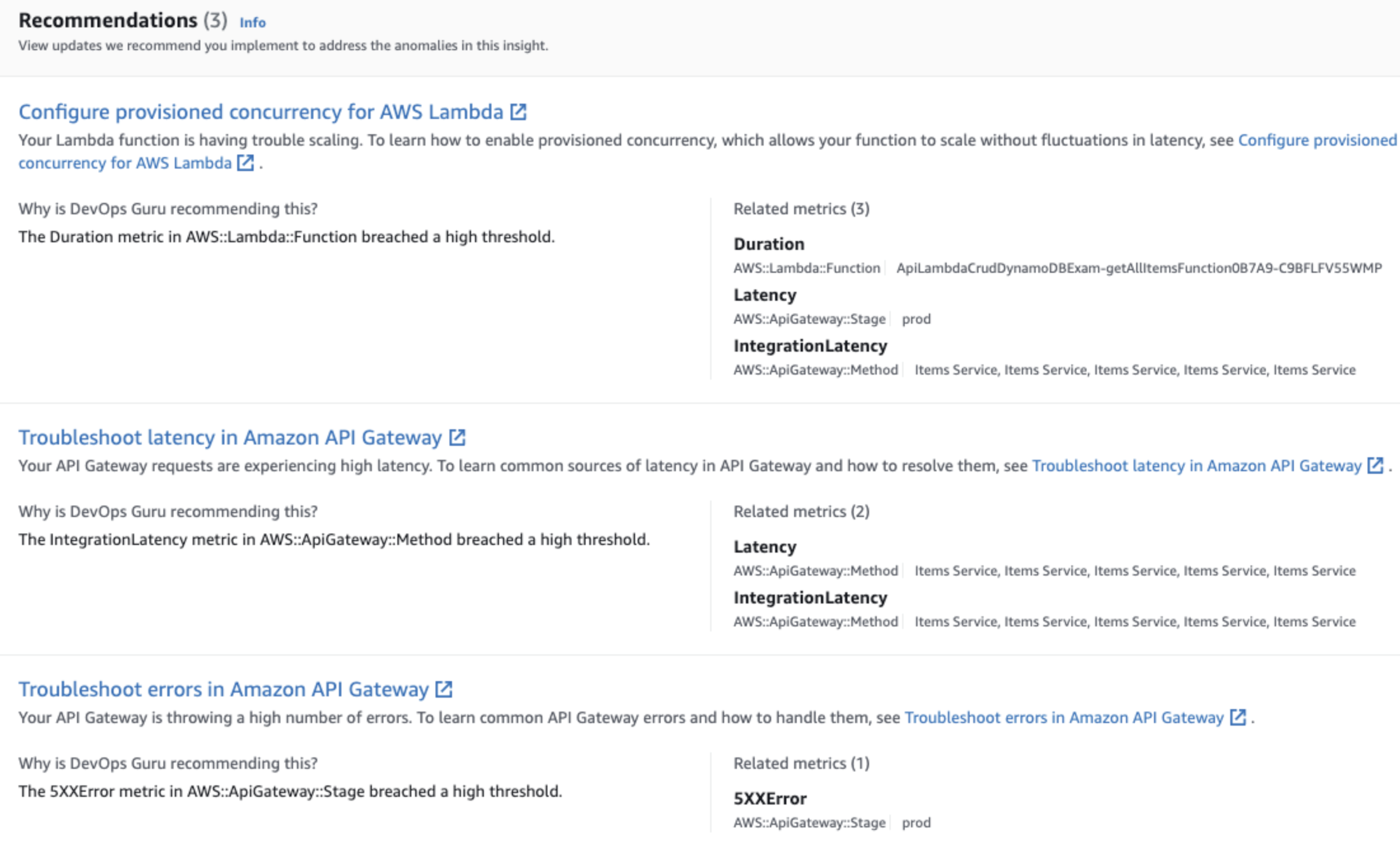
Recommendations
위에서 이상 현상을 다각적으로 분석하여 보여줬다면, Recommendations 은 문제 해결을 위한 권장 사항 가이드와 함께
문제가 발생된 근본 원인이 무엇인지 분석된 정보와 연관된 메트릭 및 상세 정보를 확인할 수 있습니다.
Integrations
DevOps Guru 에 의해 생성되는 Insights 를 OpsItem 을 통해 AWS Systems OpsCenter 로 통합 될 수 있습니다.
또한 3rd-party 벤더인 Atlassian Opsgenie 와 PagerDuty 와도 통합이 가능합니다.

Insights 자체에 포함된 정보를 기반으로 잘 설계된 Workflow 를 적용하여 사람의 개입 없이도 안정적인 운영 환경을 맞춰 갈 수 있도록 자동화된 DevOps 프로세스를 개선해 나갈 수 있습니다.
Workflow 예시로 다음과 같은 기능들을 추가할 수 있습니다.
- 구독 / 처리할 올바른 담당자 지정
- 애러 / 경고에 대한 필터링
- 알림 확장 / 에스컬레이션 과 같은 효과적인 관리
- 알려진 이벤트에 대응하는 스크립트로 자동화된 처리
- 기타 사용자 편의 UI 및 추가 기능
이 글을 보고 있는 여러분도 DevOps Guru OpenAPI 를 통해 Insights 를 수집하고 독자적인 Workflow 를 설계하여 솔루션을 구현 할 수 있습니다.
참고로, AWS Systems OpsCenter 는 Runbook 으로 알려진 시스템 관리 문서를 제공 하고 있고, Runbook 은 문제 유형별 Workflow Rule 을 관리 할 수 있으며 문제를 자동으로 처리 하기도 합니다.

Conclusion
DevOps 영역 전체를 커버하는 것은 아닙니다. 배포된 애플리케이션 서비스가 안정적으로 운영되도록 돕는 서비스이고 10년 이상된 IT 운영 전문가가 옆에서 조언해주는것과 같은 안정감을 주지 않을까? 라는 기대로 정리 할 수 있을것 같습니다.
비용은 워크로드 규모에 따라 천차만별 이겠지만 DevOps 체계를 빠르게 체득 하고자 하는 Start-Up 이나 현재 대규모 인스턴스에 다양한 문제들을 빠르게 식별 하고 즉각적인 솔루션을 필요로 하는 Enterprise 기업에겐 추천하고 싶네요.
그리고 효과적이고 보다 정확한 Insights 를 제공 받으려면 CloudWatch, CloudTrail, AppConfig, X-Ray, CodeDeploy, CloudFormation 등의 운용을 위한 AWS 리소스를 구성 하는것이 좋습니다.
반대로 Cloud 프로비저닝을 Terraform 과 같은 Opensource 로 사용하게 되면 Insights 와 연관된 이벤트로 Stack 을 식별해 낼 수 있을지 의문이긴 합니다.